

 チップス
チップスボス~!
また深夜にサーバーダウンのアラートで起こされました…。
手動で再起動してログを目視チェックするの、もう限界です。
付箋に書いた手順書もどこか行っちゃったし…。
 ボス
ボスやれやれ、チップス。
いつまでそんな『昭和の運用』をしているんだ?
その悩み、SRE(Site Reliability Engineering)の考え方を取り入れれば解決するぞ。
市場価値も桁違いだ。
「インフラエンジニアとしてのキャリアに限界を感じている」
「障害対応やルーチンワーク(トイル)に忙殺されている」
あなたも、このような悩みを抱えていないでしょうか。
- 毎日の障害対応で、新しい技術を学ぶ時間がない
- 手作業のオペレーションが多く、ミスが怖い
- 今のままでは市場価値が上がらない気がする
実は、従来の運用手法からSREへシフトすることで、業務効率だけでなく年収や市場価値も劇的に向上させることが可能です。
- SREとインフラ・DevOpsの決定的な違い
- 年収1,000万円を目指せる具体的なスキルセット
- 現場で求められる「リアルな」仕事内容
- セキュリティを武器にした生存戦略
この記事を読むことで、あなたは「守りの運用者」から「攻めのエンジニア」へと生まれ変わるためのロードマップを手に入れられます。
ぜひ最後までご覧ください。
※この記事の内容は以下のスライドでもご確認いただけます!
>SREエンジニアのスライドをダウンロードする
SREエンジニアとは? インフラ・DevOpsとの決定的な違い
多くのエンジニアが混同しがちな「SRE」「インフラエンジニア」「DevOps」。
ここでは、それぞれの明確な定義と役割の違いについて、実務レベルで解説します。
SREエンジニアの基本的な定義

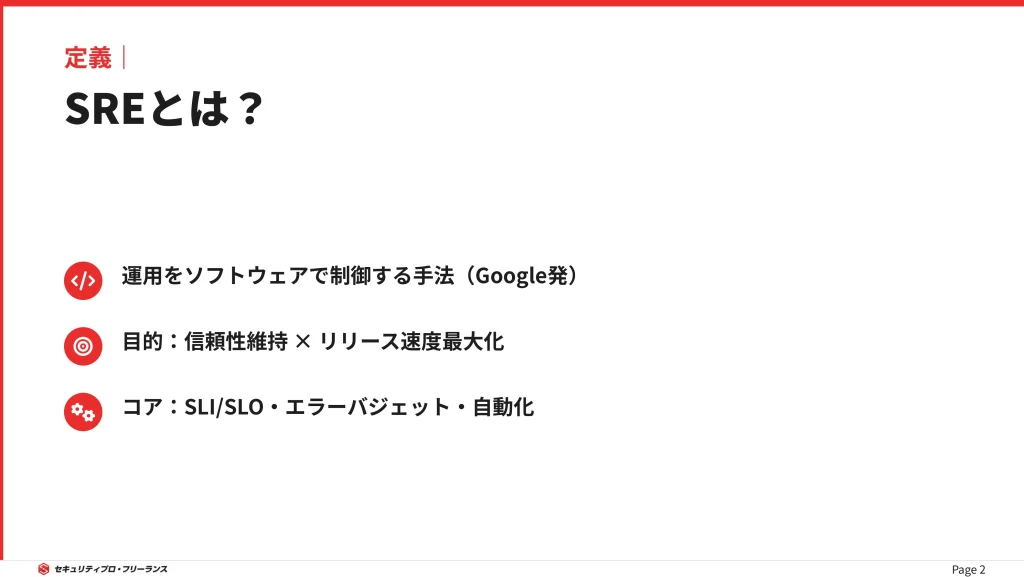
SRE(Site Reliability Engineering)とは、Googleが提唱したシステム管理の手法であり、それを実践するエンジニアの職種名を指します。
従来の運用担当者が手作業で行っていたシステム管理を、ソフトウェアエンジニアリングのアプローチで解決することが最大の特徴です。
つまり、「運用をソフトウェアで制御する」ことがSREの本質といえます。
Googleの定義によれば、SREの目的はシステムの「信頼性(Reliability)」を維持しながら、機能リリースの速度を最大化することにあります。
SREと従来の運用には、以下のような違いがあります。
| 項目 | 従来の運用(インフラ) | SRE(サイト信頼性エンジニアリング) |
|---|---|---|
| 目標 | システムを落とさない(稼働率100%) | エラーバジェット内でリスクを許容する |
| 手段 | 手順書に基づく手動オペレーション | コードによる自動化と自律回復 |
| 障害対応 | とにかく復旧させ、再発防止を誓う | ポストモーテムで根本原因を仕組みで解決する |
| 関係性 | 開発チームと対立しがち | 開発チームと目標を共有する(SLO) |
このように、SREは単なる職種名ではなく、システム運用のパラダイムシフトそのものです。
出典:Google – Site Reliability Engineering
インフラエンジニアとの決定的な違いは「コードへの向き合い方」

インフラエンジニアとSREの決定的な違いは、インフラ構築・運用において「コード(プログラム)」をどれだけ主軸に置いているかという点にあります。
従来のインフラエンジニアは、GUI(管理画面)やCLIでのコマンド手打ちによってサーバーを構築・設定することが一般的でした。
一方、SREはこれらをすべてコード化(IaC: Infrastructure as Code)し、ソフトウェア開発と同じサイクルでインフラを管理します。
具体的には、以下のような行動様式の違いとして現れます。
- インフラエンジニア:SSHでサーバーにログインし、設定ファイルを直接書き換える。
- SRE:TerraformやAnsibleのコードを修正し、Gitにコミットして自動適用させる(GitOps)。
SREにとって、サーバーの中身を手動で弄ることは「アンチパターン」とされます。
なぜなら、手動変更は再現性を損ない、オペレーションミスの温床になるからです。
「Immutable Infrastructure(不変のインフラ)」という概念に基づき、サーバーにパッチを当てるのではなく、新しい設定済みのサーバーごと入れ替えるアプローチを取るのがSRE流といえます。
DevOpsは「文化」、SREは「実装」クラス
「DevOps」と「SRE」の関係性についても整理しておきましょう。
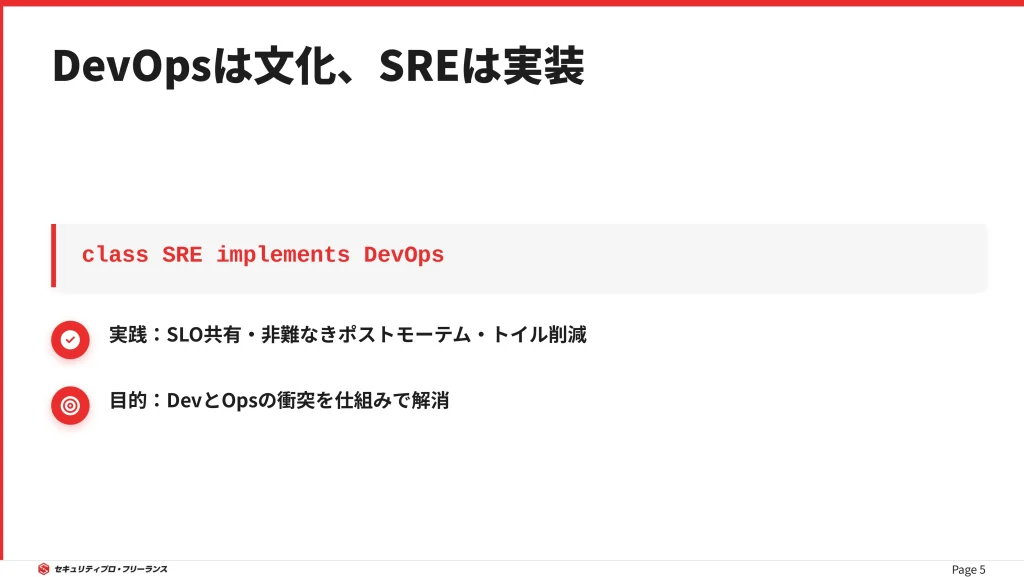
結論からいうと、DevOpsは「開発(Dev)と運用(Ops)が協力し合う文化や思想」であり、SREはその思想を具体的に実現するための「実装(職種・方法論)」です。
GoogleのSREチームは、この関係を「class SRE implements DevOps」(SREクラスはDevOpsインターフェースの実装である)と表現しています。
DevOpsが掲げる抽象的な目標を、SREは具体的なアクションに落とし込みます。
- DevOpsの思想:「組織のサイロ化を防ぐ」
→ SREの実践:SLO(サービスレベル目標)やエラーバジェットを共有言語として導入する。 - DevOpsの思想:「失敗を許容する」
→ SREの実践:Blameless Post-mortem(非難なき事後検証)を実施する。 - DevOpsの思想:「自動化を推進する」
→ SREの実践:トイル(労役)を削減し、エンジニアリングに時間を割く。
SREは、DevOpsという理想郷に到達するための具体的な「乗り物」と考えると理解しやすいでしょう。
SREエンジニアの「リアルな」仕事内容と使用ツール

 チップス
チップスなるほど~。
でもボス、実際にはどんなツールを使って、どんな作業をしてるんですか?
まさか1日中コード書いてるわけじゃないですよね?
 ボス
ボスいい質問だ。
SREの仕事は多岐にわたる。
泥臭い交渉から、高度なセキュリティ実装まで、現場のリアルを見ていこう。
1. 【設計・交渉】SLO(サービスレベル目標)の策定とエラーバジェット管理
SREの業務において最も重要かつ最初に行うべきは、SLI(Service Level Indicator)の選定とSLO(Service Level Objective)の策定です。
これは単に数値を決めるだけでなく、ビジネスサイド(プロダクトオーナーなど)との「合意形成」がメインタスクとなります。
例えば、「トップページの表示速度」をSLIとし、「99.9%のリクエストを2秒以内に返す」といったSLOを設定します。
重要なのは、100%を目指さないことです。
100%を目指すとコストが指数関数的に増大するため、あえて「失敗してもよい余白」としてエラーバジェット(Error Budget)を設定します。
- SLI(指標):何を測るか(例:レイテンシ、エラー率)。
- SLO(目標):ユーザーが満足する閾値(例:99.9%)。
- エラーバジェット:1 – SLO(例:残り0.1%)。
エラーバジェットが残っているうちは開発チームは新機能をリリースできますが、使い切ったらリリースを凍結し、信頼性向上にリソースを全振りします。
この「リリース可否の判断基準」を運用するのがSREの役目です。
2. 【構築・実装】IaC(Infrastructure as Code)と「自律回復」の実装
SREはインフラの構築・変更をすべてコードで行います。
これにより、誰がいつ何を変更したかがGitの履歴に残り、ミスがあればすぐに切り戻す(ロールバック)ことが可能になります。
主な使用ツールと用途は以下の通りです。
| ツール | 用途 | 役割 |
|---|---|---|
| Terraform | クラウドインフラ構築 | VPC、EC2、ロードバランサーなどの構成管理 |
| Ansible | OS設定・ミドルウェア導入 | サーバー内部の設定自動化 |
| Kubernetes | コンテナオーケストレーション | アプリケーションの自動デプロイ、スケーリング |
| Helm | Kubernetesパッケージ管理 | k8sマニフェストのテンプレート管理 |
さらに重要なのが「自律回復(Auto Healing)」の実装です。
例えば、Kubernetesを用いて「プロセスが落ちたら自動で再起動する」「アクセスが増えたら自動でサーバーを増やす(オートスケール)」といった仕組みを作り込みます。
夜中に叩き起こされないインフラを作ることこそ、SREの腕の見せ所といえます。
3. 【可観測性】単なる監視ではない「Observability」の導入と分析
従来の監視(Monitoring)が「サーバーが生きているか(死活監視)」や「CPU使用率」を見ていたのに対し、SREは「Observability(可観測性)」を重視します。
これは「システム内部の状態を外部出力(ログ、メトリクス、トレース)からどれだけ推測できるか」という能力を指します。
「なぜ遅いのか?」「どこでエラーが起きているのか?」を即座に特定するために、DatadogやNew Relic、Prometheusといったツールを活用し、分散トレーシングや詳細なログ分析環境を構築します。
また、SREにとってログ分析と監視は必須スキルです。
SplunkやEDR製品(CrowdStrike、Defender for Endpoint)などのSIEMツールを活用したセキュリティログ分析の実務案件も多数存在しており、Observabilityのスキルを実践で活かせます。
これらを駆使して「未知の不具合」に気づける状態を作ることが求められます。
4. 【効率化】トイル(Toil)撲滅のためのツール開発(ChatOpsなど)
Googleは、SREの業務において「手作業による運用(トイル)」を50%以下に抑えることを推奨しています。
残りの50%は、トイルをなくすためのエンジニアリング(開発)に充てるべきという考え方です。
トイルとは、以下のような特徴を持つ作業を指します。
- 手動であること
- 繰り返されること
- 自動化が可能であること
- 長期的価値がないこと
- サービスの成長に比例して増加すること
SREはPythonやGo言語を用いて、これらの作業を自動化するツールを開発します。
例えば、Slackなどのチャットツールからコマンドひとつでデプロイやサーバー再起動ができる「ChatOps」環境(Bot)を構築し、開発者が自己解決できる仕組みを提供します。
「自分が楽をするために、全力を出してコードを書く」。
これがSREの行動原理です。
5. 【緊急対応】オンコール対応と「ポストモーテム(事後検証)」
システム障害が発生した際、SREは「オンコール担当」として一次対応を行います。
PagerDutyなどのツールから通知を受け取り、迅速に復旧作業にあたります。
しかし、SREの真価が問われるのは復旧後です。
関係者を集めて「ポストモーテム(事後検証)」を実施します。
ここでは「誰が間違えたか」を追及することは厳禁です(Blameless文化)。
「なぜヒューマンエラーが起きる仕組みだったのか」「どうすれば自動で防げたか」を徹底的に議論し、再発防止策をコードやプロセスに落とし込みます。
- 事実の確認:タイムライン形式で何が起きたか整理する
- 根本原因の特定:Whyを5回繰り返して真因を探る
- 再発防止策:精神論ではなく、仕組みで解決するタスクを決める
ポストモーテムの成果物はドキュメントとして残し、組織の共有資産とします。
失敗を糧にしてシステムを強くするプロセスこそがSREの醍醐味といえます。
6. 【セキュリティ】DevSecOpsの実装(CI/CDへの脆弱性診断)
近年、SREの役割として重要視されているのが「セキュリティの自動化」、すなわちDevSecOpsです。
開発スピードを損なわずにセキュリティを担保するため、CI/CDパイプラインの中にセキュリティチェックを組み込みます。
具体的には以下のような実装を行います。
- IaCスキャン:Terraformコードのセキュリティ不備(S3の公開設定など)をデプロイ前に検知(Trivy, Checkovなど)。
- コンテナスキャン:Dockerイメージに含まれる脆弱性を自動チェック。
- SAST/DAST:静的・動的アプリケーションセキュリティテストの自動実行。
CI/CDパイプラインへのセキュリティテスト組み込みやSAST/DAST導入など、DevSecOpsの実装経験は市場価値を大きく高めます。
実際にDevSecOps関連のセキュリティ案件では、月額100万円程度の高単価案件も存在します。
セキュリティを「人のチェック」から「システムによるガード」に変えることも、信頼性エンジニアリングの一部なのです。
SREエンジニアの「ある1日」のスケジュール例

SREの働き方は、フェーズや組織によって異なりますが、開発と運用のハイブリッドな動きをするのが一般的です。
以下に、あるSREエンジニアの1日のスケジュール例を紹介します。
夜間のバッチ処理結果や、SLOダッシュボード(Datadog)を確認します。
エラーバジェットの消費状況をチームチャットに共有します。
開発チームと進捗共有。
昨日のデプロイによる影響がないか、今日のリリース予定を確認します。
新規マイクロサービスのインフラ構成をTerraformで記述。
GitHubでPull Requestを作成し、相互レビューを行います。
手動で行っていた証明書更新作業を自動化するためのPythonスクリプトを作成・検証。
Lambdaにデプロイして定期実行化します。
先週発生したレイテンシ悪化の事後検証会議をファシリテート。
再発防止策としてRedisのキャッシュ設定見直しを決定します。
新しいコンテナセキュリティツール(Trivy)の検証環境への導入テストを行います。
突発的な障害対応が入ることもありますが、基本的には計画的な「信頼性向上のための開発」に時間を割くようコントロールするのがSREの流儀です。
年収1,000万円も?SREエンジニアの年収相場と将来性
 チップス
チップス仕事内容はわかりましたけど、ぶっちゃけ儲かるんですか?
ボスみたいにリッチになれますか?
 ボス
ボスふふふ。
SREは今、最も需給バランスが崩れている職種のひとつだ。
スキル次第では1,000万など通過点に過ぎないぞ。
SREの平均年収と求人動向
SREエンジニアの年収水準は、一般的なインフラエンジニアと比較して明らかに高い傾向にあります。
求人ボックスや転職ドラフトなどの公開データを参考にすると、SREの平均年収はおおよそ以下のようなレンジになっています。
- ジュニアクラス:500万円〜700万円
- ミドルクラス:700万円〜1,000万円
- シニア・リードクラス:1,000万円〜1,500万円以上
特に、メガベンチャーや外資系企業、急成長中のSaaS企業では、サービスの信頼性が売上に直結するため、優秀なSREには予算を惜しまない傾向があります。
求人動向としても、クラウドネイティブな開発が標準化する中で、AWS/GCPの知見とコードが書ける運用担当者の需要は右肩上がりです。
従来の「サーバー監視員」の求人が減る一方で、SREの求人は増加の一途を辿っています。
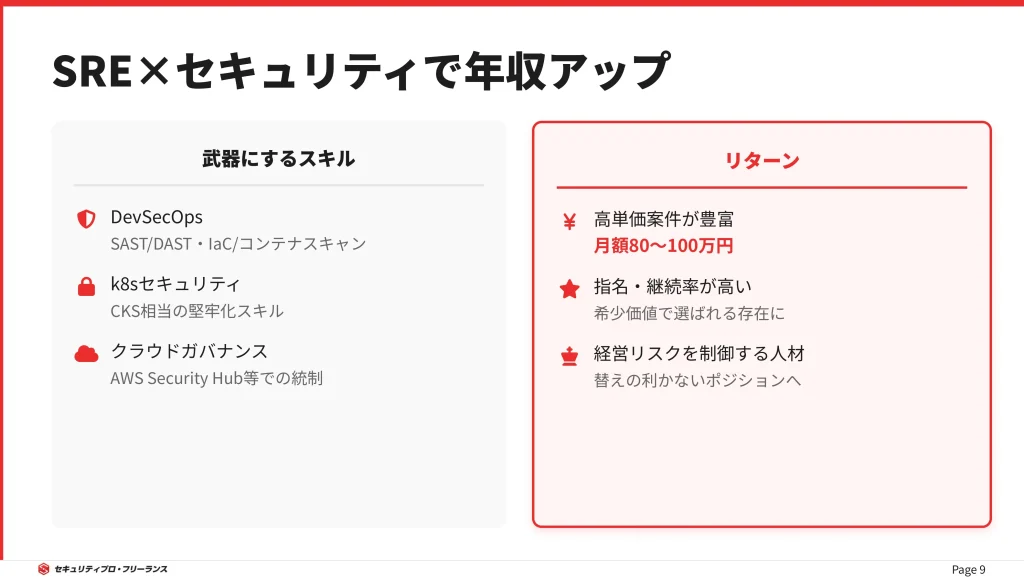
「SRE×セキュリティ」で市場価値はさらに跳ね上がる
高年収を狙うSREの中でも、特に希少価値が高いのが「セキュリティスキル」を持った人材です。
インフラ構築や自動化ができるSREは増えてきましたが、「堅牢なセキュリティ設計」や「インシデント対応」までカバーできる人材は極めて少ないのが現状です。
- Kubernetesのセキュリティ設定(CKS相当)ができる
- AWS Security Hubを活用したガバナンス構築ができる
- 脆弱性対応の自動化フローを設計できる
SREとセキュリティのスキルを兼ね備えた人材は希少であり、セキュリティ領域のフリーランス案件では月額80万円以上の高単価案件が80%以上を占めています。
セキュリティを武器にすることで、単なる便利屋から、経営リスクをコントロールする「替えの利かない人材」へとポジションアップできるのです。
未経験・インフラ担当からSREになるためのロードマップ

ここからは、現在インフラエンジニアや開発エンジニアとして働いている人が、SREへキャリアチェンジするための具体的なステップを紹介します。
習得すべき必須スキルとツール
SREを目指すなら、まずは「脱GUI」「脱手動」を意識してスキルを習得していく必要があります。
具体的な学習優先度は以下の通りです。
コンソール画面ではなく、サービスの仕組み(VPC, IAM, EC2/Compute Engine)を深く理解する。
インフラをコードで定義できるようにする。
まずは既存環境のコード化から始めるとよいでしょう。
現代のWebアプリケーション基盤のデファクトスタンダード。
概念だけでなく、実際に動かして学びます。
運用ツール作成のためのスクリプト言語。
APIを叩いて自動化する処理を書けるようにします。
テストとデプロイの自動化パイプラインを構築するスキルです。
まずは自宅でクラウド環境を契約し、小さなWebアプリをTerraformとCI/CDを使って自動デプロイする環境を作ってみるのが一番の近道です。
SREエンジニアにオススメの資格
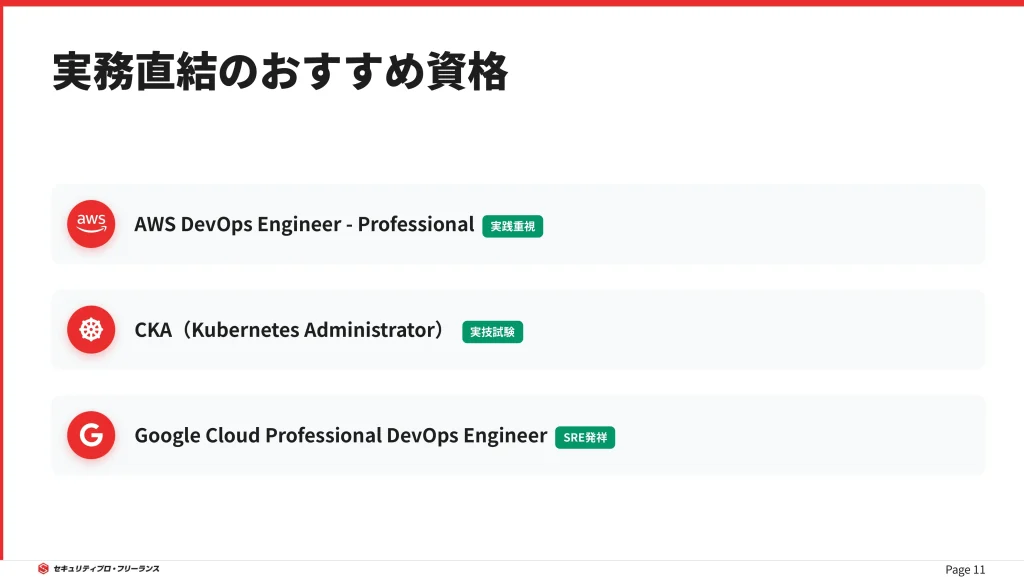
実務経験が不足している場合、資格取得は知識の証明として有効です。
特にSREの実務に直結する以下の資格を推奨します。
- AWS Certified DevOps Engineer – Professional
AWS上でのCI/CD、モニタリング、自動化に関する高度な知識を証明します。 - CKA (Certified Kubernetes Administrator)
Kubernetesの管理者スキル。
実技試験であるため、現場での評価が高い資格です。 - Google Cloud Professional Cloud DevOps Engineer
SREの発祥であるGoogle Cloudの思想と実践スキルを体系的に学べます。
これらのスキルを習得した後は、セキュリティ専門のフリーランスエージェントに相談することで、SREエンジニアとしての最適なキャリアパスを描けます。
資格勉強を通じて体系的な知識を身につけ、それをポートフォリオ(GitHub上のコードなど)でアウトプットすることが重要です。
SREエンジニアの将来性:「セキュリティ」が最強の武器になる理由

生成AIの台頭により、「単純なコードを書くだけ」のエンジニアの価値は今後低下していくと予想されます。
しかし、SREの将来性は依然として明るいといえます。
なぜなら、SREの本質は「ビジネス要件とシステム信頼性のバランス調整」という高度な判断業務にあるからです。
特に「セキュリティ」は、AIに丸投げできない経営上の最重要課題です。
クラウドネイティブなSREエンジニアにとって、Zscaler、Palo Alto、CrowdStrikeなどのクラウドセキュリティ製品の知見は市場価値を飛躍的に高めます。
実際にクラウドセキュリティ案件では月額80〜100万円の案件が豊富にあります。
「システムを止めない」だけでなく「システムを守る」ことができるSREは、どのような時代になっても企業から熱望される存在であり続けるでしょう。
まとめ
 ボス
ボスどうだチップス。
パスワードを付箋に書いて貼るなんてリスは、もう卒業できそうか?
 チップス
チップスはいっ!
僕もSecrets Managerを使ってパスワードレスな世界を目指します!
Terraformの勉強も始めます!
SREエンジニアは、インフラエンジニアの単なる延長線上にある職種ではありません。
エンジニアリングの力で運用を変革し、ビジネスの成長を支える重要なポジションです。
最後に、SREを目指すためのポイントを振り返りましょう。
- SREはコードでインフラを管理し、信頼性をエンジニアリングする。
- トイル(手作業)を削減し、自動化や改善に時間を投資する。
- SLOやエラーバジェットを用いて、開発と運用の対立を解消する。
- セキュリティスキル(DevSecOps)を掛け合わせることで、年収1,000万円以上も現実的になる。
もしあなたが今の環境に閉塞感を感じているなら、まずは小さな自動化から始めてみてください。
そして、SREエンジニアとしてのキャリアをさらに加速させたい方は、セキュリティ専門のフリーランス案件をチェックしてみてください。
あなたのスキルを高く評価してくれる場所は必ずあります。


